library(paneldesc)3 Basic example
Below is an example showing the basic usage of all the package’s functions.
3.1 Set up
Import the package.
3.2 Data import
Import the built-in dataset with simulated unbalanced panel data.
data(production)3.3 Panel data structure analysis
The first group of functions is designed to analyze the structure of the panel.
To begin with, you can look at the basic characteristics of the panel: the number of entities, the number of periods, the number of rows, and the number of variables.
describe_dimensions(production, index = c("firm", "year"))| rows | entities | periods | variables |
|---|---|---|---|
| 180 | 30 | 6 | 5 |
To begin analyzing the balance of the panel, you can look at the representation of entities by period.
describe_periods(production, index = c("firm", "year"))| year | count | share |
|---|---|---|
| 1 | 25 | 0.833 |
| 2 | 28 | 0.933 |
| 3 | 30 | 1.000 |
| 4 | 29 | 0.967 |
| 5 | 26 | 0.867 |
| 6 | 19 | 0.633 |
For a more detailed analysis of the panel balance, you can look at the distribution of the number of entities by periods and the number of periods by entities.
describe_balance(production, index = c("firm", "year"))| dimension | mean | std | min | max |
|---|---|---|---|---|
| entities | 26.167 | 3.971 | 19 | 30 |
| periods | 5.233 | 0.935 | 3 | 6 |
You can also visualize the distribution of the number of periods across entities.
plot_periods(production, index = c("firm", "year"))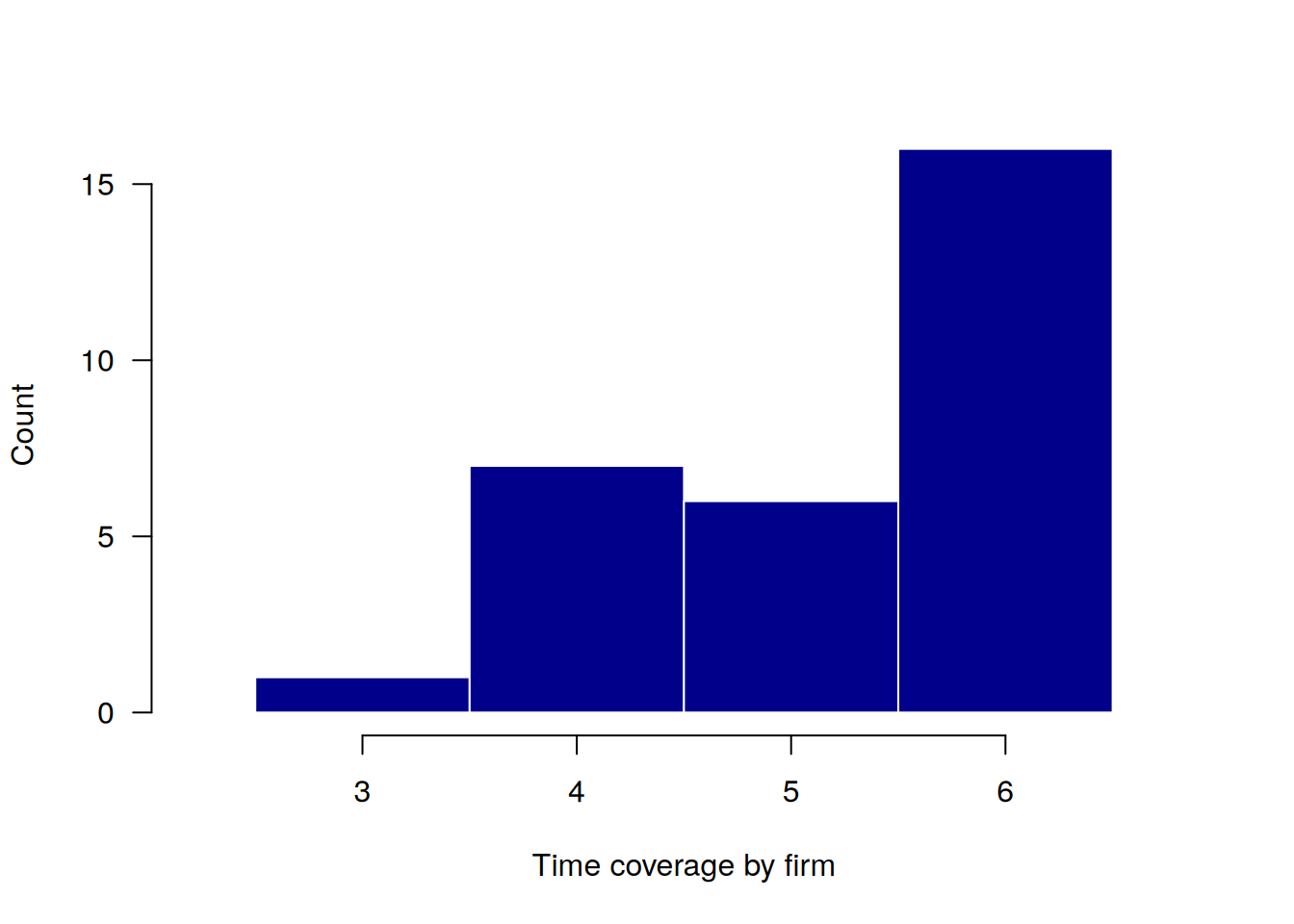
In addition, the main patterns of entities participation in the panel can be displayed in a table or graph.
describe_patterns(production, index = c("firm", "year"))| pattern | 1 | 2 | 3 | 4 | 5 | 6 | count | share |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 16 | 0.533 |
| 2 | 1 | 1 | 1 | 1 | 1 | 0 | 5 | 0.167 |
| 3 | 1 | 1 | 1 | 1 | 0 | 0 | 3 | 0.100 |
| 4 | 0 | 0 | 1 | 1 | 1 | 1 | 2 | 0.067 |
| 5 | 0 | 1 | 1 | 1 | 1 | 0 | 2 | 0.067 |
| 6 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0.033 |
| 7 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0.033 |
plot_patterns(production, index = c("firm", "year"))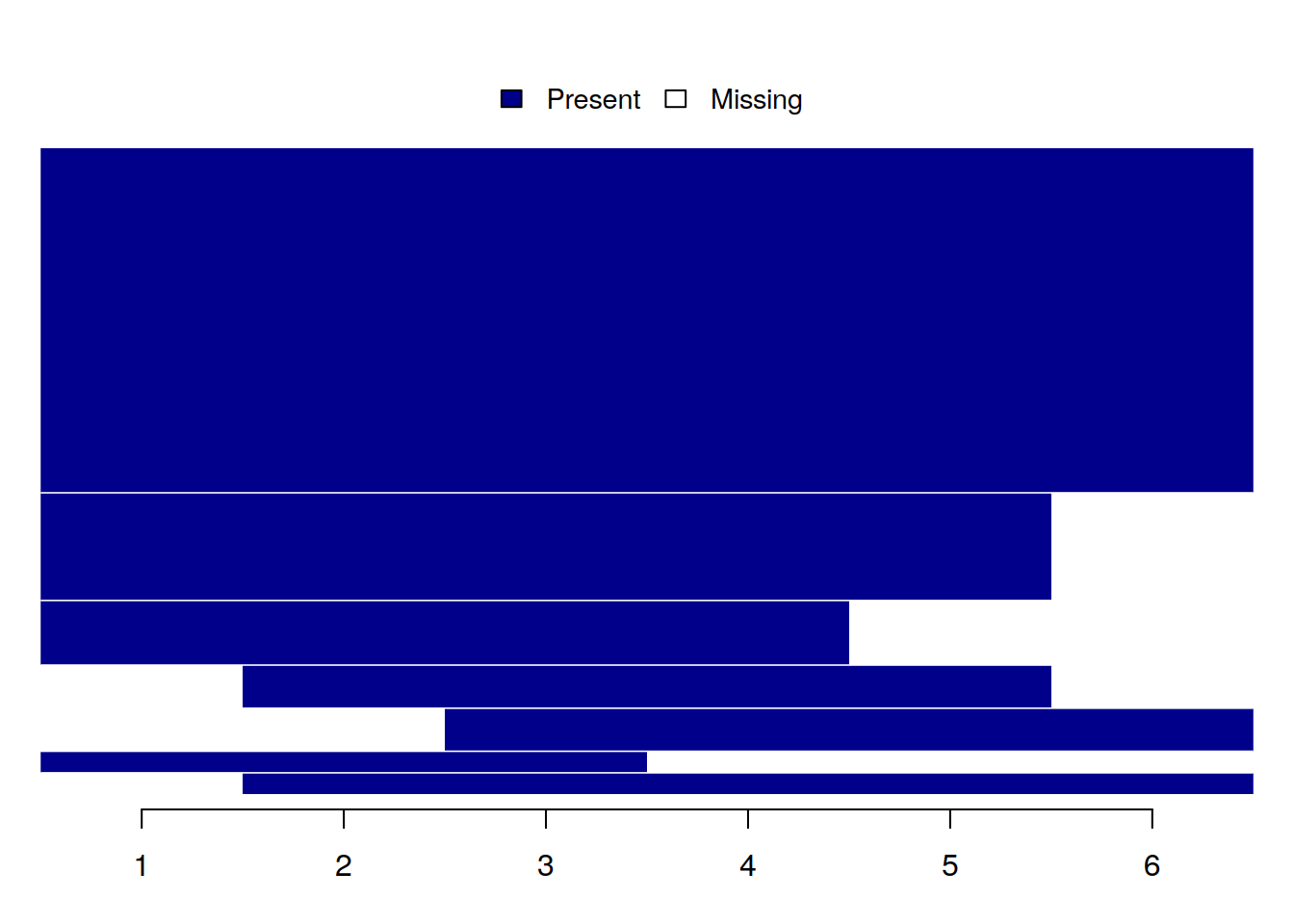
3.4 Missing values analysis
The second group of functions is aimed at analyzing missing values, taking into account the nature of panel data.
You can create a heatmap showing the number of missing values for each variable across all time periods.
plot_missing(production, index = c("firm", "year"))Analysing all variables: sales, capital, labor, industry, ownership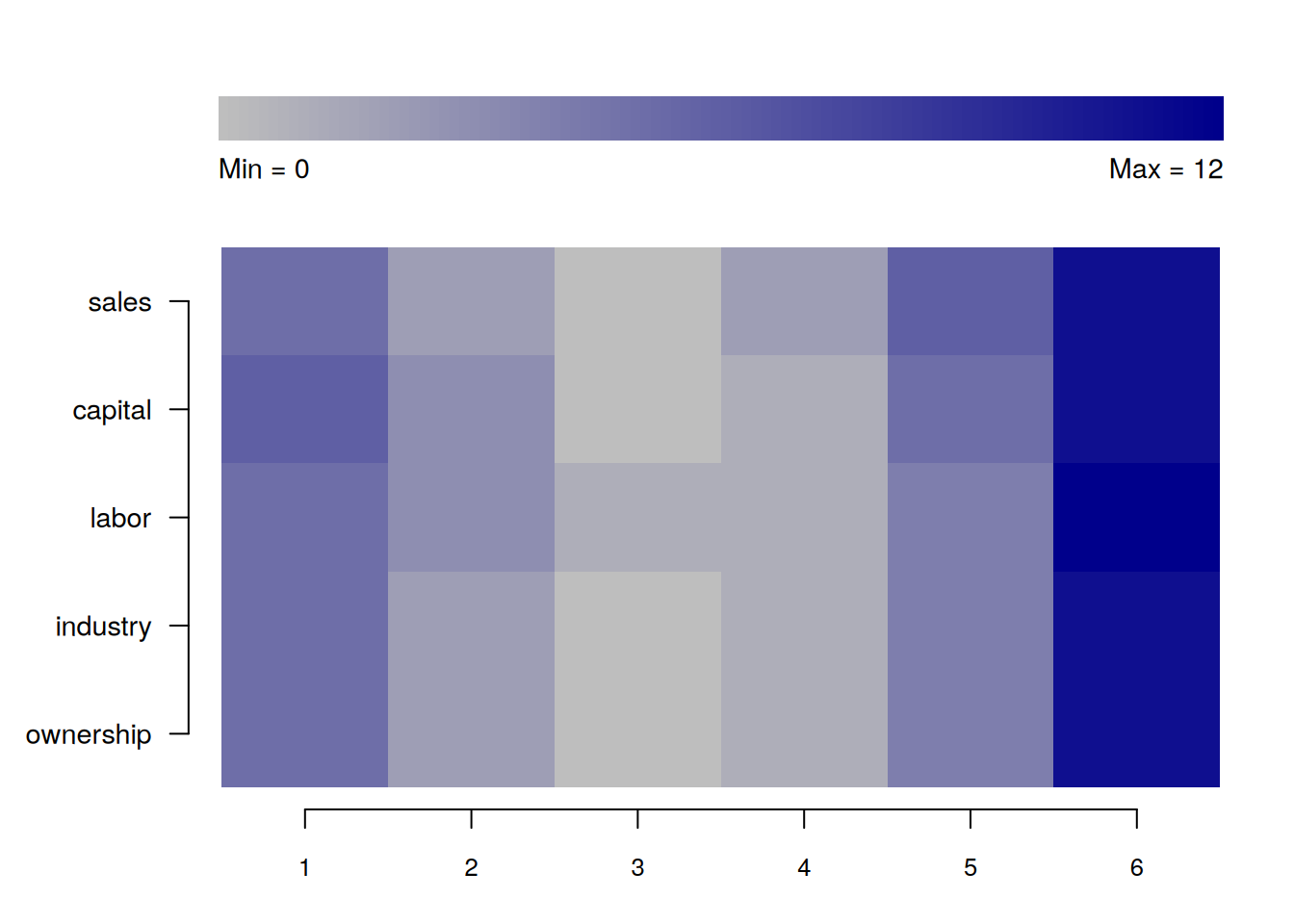
Also, you can output the table with brief summary statistics on missing values.
summarize_missing(production, index = c("firm", "year"))Analyzing all variables: sales, capital, labor, industry, ownership| variable | na_count | na_share | entities | periods |
|---|---|---|---|---|
| sales | 26 | 0.144 | 15 | 5 |
| capital | 26 | 0.144 | 17 | 5 |
| labor | 26 | 0.144 | 16 | 6 |
| industry | 23 | 0.128 | 14 | 5 |
| ownership | 23 | 0.128 | 14 | 5 |
In addition, you can compare missing values statistics across various entities.
describe_incomplete(production, index = "firm")| firm | na_count | variables |
|---|---|---|
| 23 | 15 | 5 |
| 21 | 11 | 5 |
| 1 | 10 | 5 |
| 2 | 10 | 5 |
| 6 | 10 | 5 |
| 7 | 10 | 5 |
| 12 | 10 | 5 |
| 26 | 10 | 5 |
| 25 | 6 | 5 |
| 30 | 6 | 5 |
| 4 | 5 | 5 |
| 13 | 5 | 5 |
| 17 | 5 | 5 |
| 29 | 5 | 5 |
| 8 | 2 | 2 |
| 3 | 1 | 1 |
| 10 | 1 | 1 |
| 14 | 1 | 1 |
| 24 | 1 | 1 |
3.5 Numeric variables analysis
The third group of functions is aimed at analyzing numeric variables, taking into account the nature of panel data.
If you need to, you can output a table with simple descriptive statistics.
summarize_numeric(production)Analyzing all numeric variables: firm, year, sales, capital, labor| variable | count | mean | std | min | max |
|---|---|---|---|---|---|
| firm | 180 | 15.500 | 8.680 | 1.000 | 30.000 |
| year | 180 | 3.500 | 1.713 | 1.000 | 6.000 |
| sales | 154 | 69.756 | 46.804 | 8.321 | 336.853 |
| capital | 154 | 32.490 | 31.053 | 0.968 | 194.719 |
| labor | 154 | 79.329 | 73.687 | 4.097 | 419.848 |
Descriptive statistics can be grouped by some variable, which does not necessarily have to be a panel identifier.
summarize_numeric(production, group = "year")Analyzing all numeric variables: firm, sales, capital, labor| year | variable | count | mean | std | min | max |
|---|---|---|---|---|---|---|
| 1 | firm | 30 | 15.500 | 8.803 | 1.000 | 30.000 |
| 1 | sales | 25 | 58.491 | 44.590 | 8.321 | 190.100 |
| 1 | capital | 24 | 24.862 | 16.273 | 0.968 | 65.950 |
| 1 | labor | 25 | 68.871 | 66.941 | 4.097 | 246.852 |
| 2 | firm | 30 | 15.500 | 8.803 | 1.000 | 30.000 |
| 2 | sales | 28 | 56.099 | 37.944 | 17.803 | 186.349 |
| 2 | capital | 27 | 28.790 | 31.053 | 3.150 | 151.464 |
| 2 | labor | 27 | 60.463 | 48.484 | 11.692 | 222.761 |
| 3 | firm | 30 | 15.500 | 8.803 | 1.000 | 30.000 |
| 3 | sales | 30 | 76.660 | 47.574 | 20.580 | 219.513 |
| 3 | capital | 30 | 35.464 | 39.174 | 4.729 | 194.719 |
| 3 | labor | 29 | 90.437 | 82.628 | 9.284 | 414.844 |
| 4 | firm | 30 | 15.500 | 8.803 | 1.000 | 30.000 |
| 4 | sales | 28 | 73.104 | 33.238 | 19.455 | 135.118 |
| 4 | capital | 29 | 44.522 | 35.375 | 5.080 | 132.898 |
| 4 | labor | 29 | 73.967 | 54.005 | 16.327 | 240.726 |
| 5 | firm | 30 | 15.500 | 8.803 | 1.000 | 30.000 |
| 5 | sales | 24 | 75.398 | 43.091 | 20.161 | 211.092 |
| 5 | capital | 25 | 28.351 | 23.127 | 5.339 | 86.078 |
| 5 | labor | 26 | 90.604 | 85.026 | 21.063 | 413.784 |
| 6 | firm | 30 | 15.500 | 8.803 | 1.000 | 30.000 |
| 6 | sales | 19 | 81.744 | 73.320 | 20.352 | 336.853 |
| 6 | capital | 19 | 29.767 | 30.908 | 2.288 | 108.787 |
| 6 | labor | 18 | 96.609 | 103.777 | 20.507 | 419.848 |
Heterogeneity between different groups can also be visualized.
plot_heterogeneity(production, select = "sales", group = "year")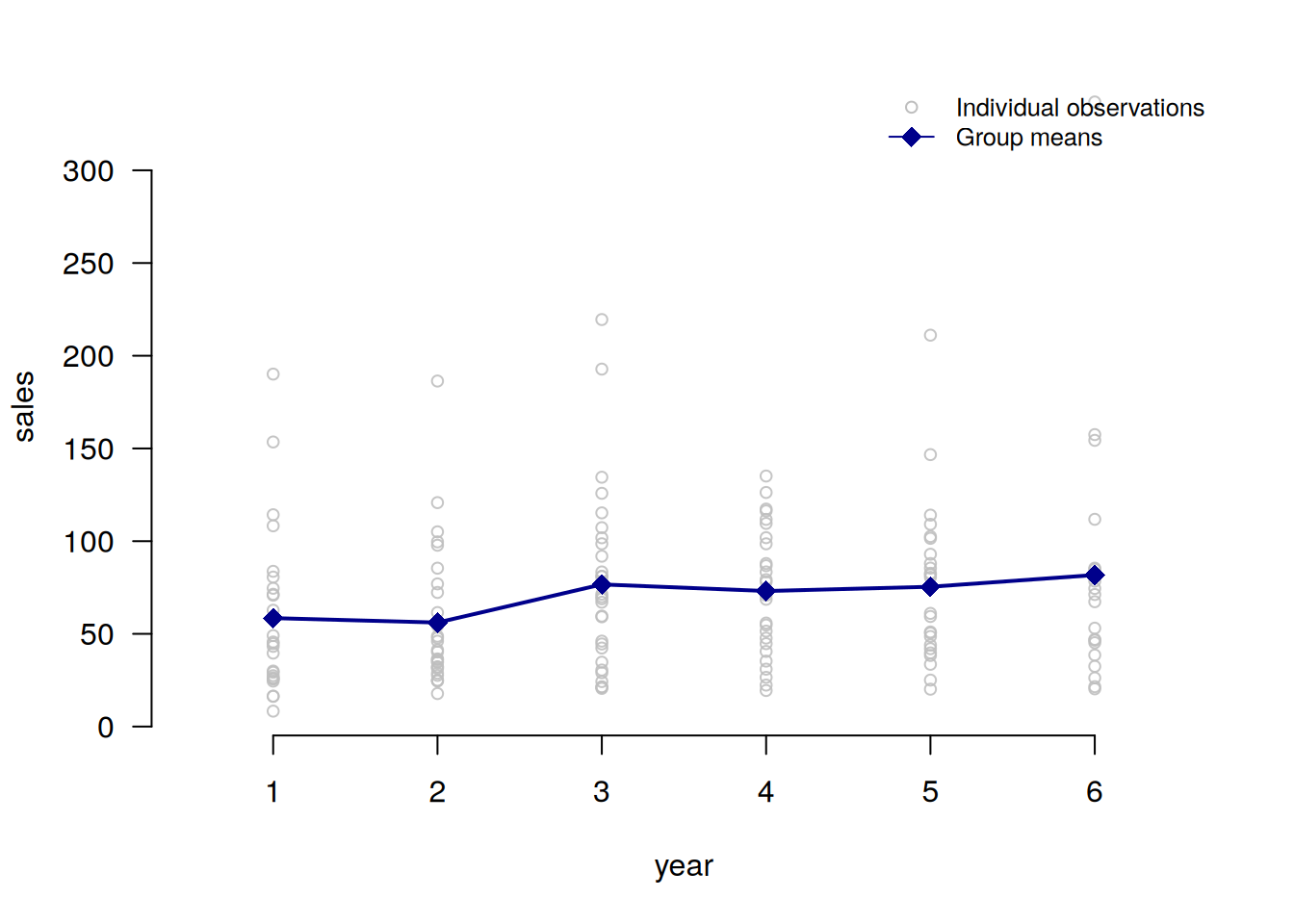
For more detailed heterogeneity analysis, numeric variables can be decomposed into between and within components.
decompose_numeric(production, index = "firm")Analyzing all numeric variables: year, sales, capital, labor| variable | dimension | mean | std | min | max | count |
|---|---|---|---|---|---|---|
| year | overall | 3.500 | 1.713 | 1.000 | 6.000 | 180.000 |
| year | between | NA | 0.000 | 3.500 | 3.500 | 30.000 |
| year | within | NA | 1.713 | 1.000 | 6.000 | 6.000 |
| sales | overall | 69.756 | 46.804 | 8.321 | 336.853 | 154.000 |
| sales | between | NA | 29.776 | 25.772 | 159.197 | 30.000 |
| sales | within | NA | 35.862 | -28.397 | 247.412 | 5.133 |
| capital | overall | 32.490 | 31.053 | 0.968 | 194.719 | 154.000 |
| capital | between | NA | 13.969 | 8.671 | 75.083 | 30.000 |
| capital | within | NA | 27.701 | -22.444 | 152.126 | 5.133 |
| labor | overall | 79.329 | 73.687 | 4.097 | 419.848 | 154.000 |
| labor | between | NA | 44.023 | 24.606 | 175.731 | 30.000 |
| labor | within | NA | 59.561 | -77.709 | 323.445 | 5.133 |
3.6 Factor variables analysis
The last group of functions is aimed at analyzing factor (categorical) variables, taking into account the nature of panel data.
Factor variables can be decomposed into between and within components.
decompose_factor(production, index = "firm")Analyzing all factor variables: industry, ownership| variable | category | count_overall | share_overall | count_between | share_between | share_within |
|---|---|---|---|---|---|---|
| industry | Industry 1 | 63 | 0.401 | 13 | 0.433 | 0.918 |
| industry | Industry 2 | 45 | 0.287 | 11 | 0.367 | 0.809 |
| industry | Industry 3 | 49 | 0.312 | 10 | 0.333 | 0.917 |
| ownership | private | 76 | 0.484 | 16 | 0.533 | 0.898 |
| ownership | public | 55 | 0.350 | 13 | 0.433 | 0.813 |
| ownership | mixed | 26 | 0.166 | 7 | 0.233 | 0.724 |
One can also summarize transitions between states of a categorical (factor) variable.
summarize_transition(production, select = "industry", index = c("firm", "year"))23 rows with NA values in 'industry' removed.| from_to | Industry 1 | Industry 2 | Industry 3 |
|---|---|---|---|
| Industry 1 | 1.000 | 0.000 | 0.000 |
| Industry 2 | 0.054 | 0.919 | 0.027 |
| Industry 3 | 0.000 | 0.025 | 0.975 |